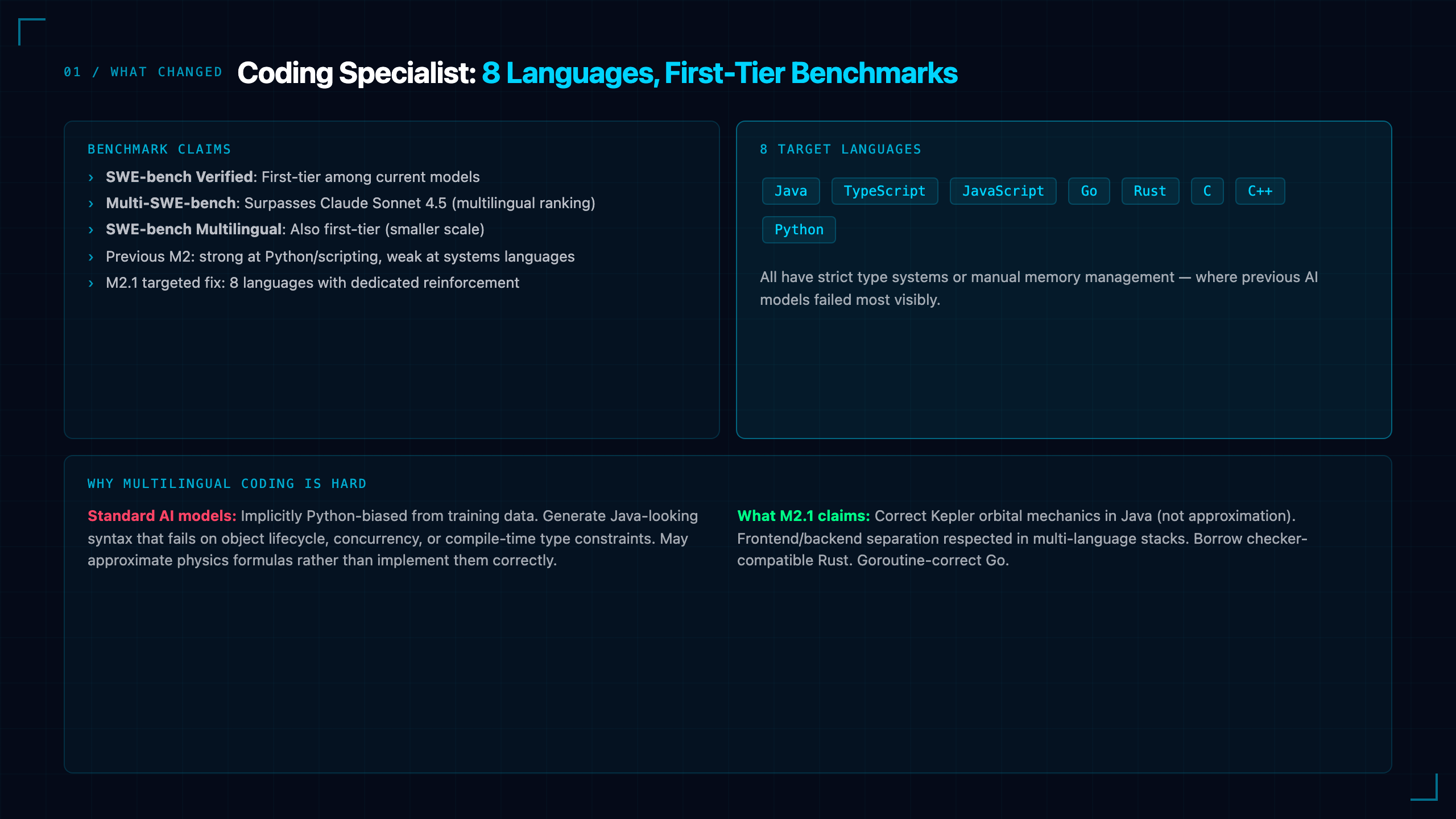
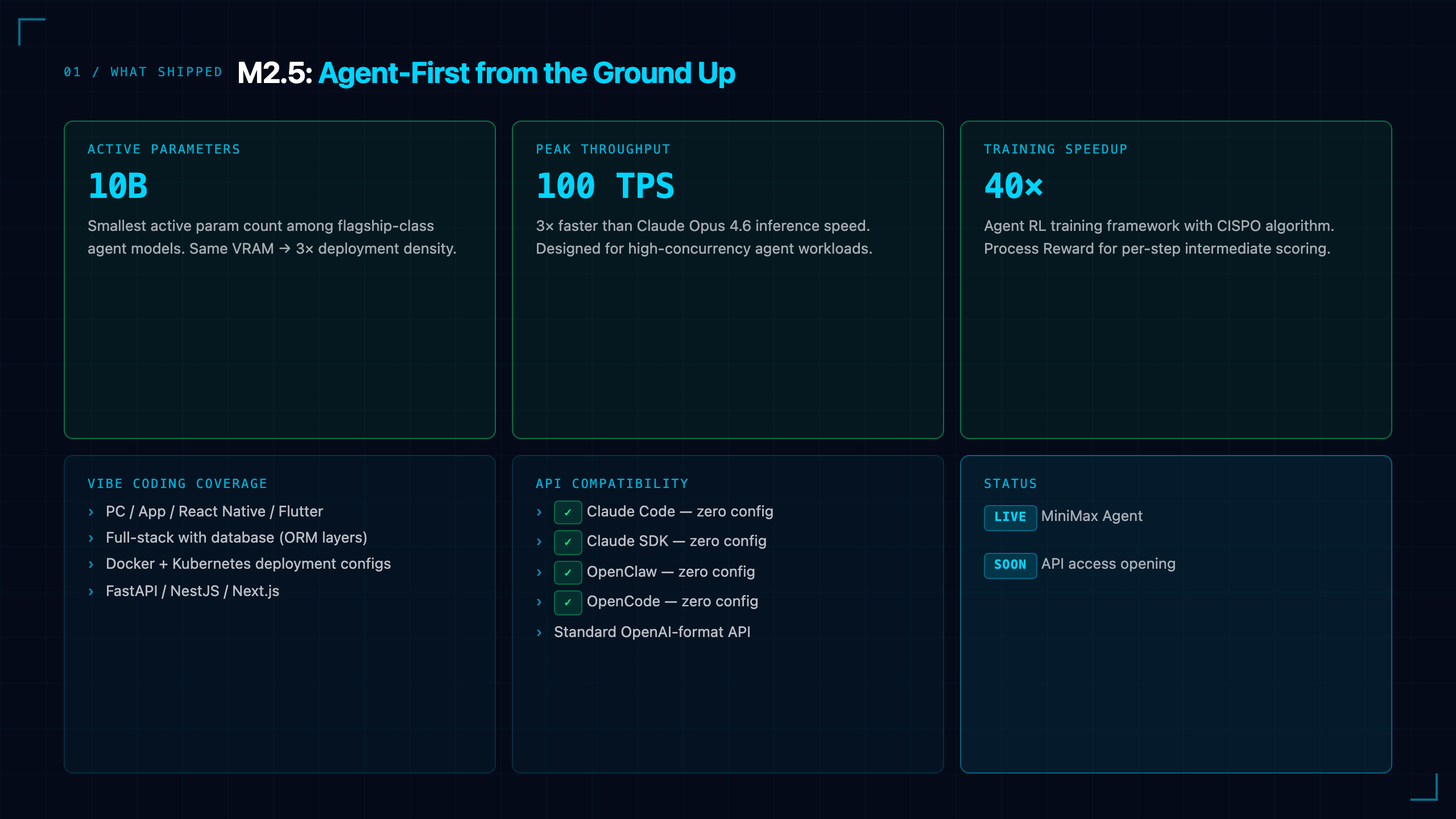
MiniMax doesn't get the attention it deserves outside China. While the world fixates on DeepSeek's efficiency story and Kimi's long-context moonshots, MiniMax has been quietly building in a different direction: sustained execution at multimodal scale.
M3 is the result. And it's a meaningful step change.
What's New in M3
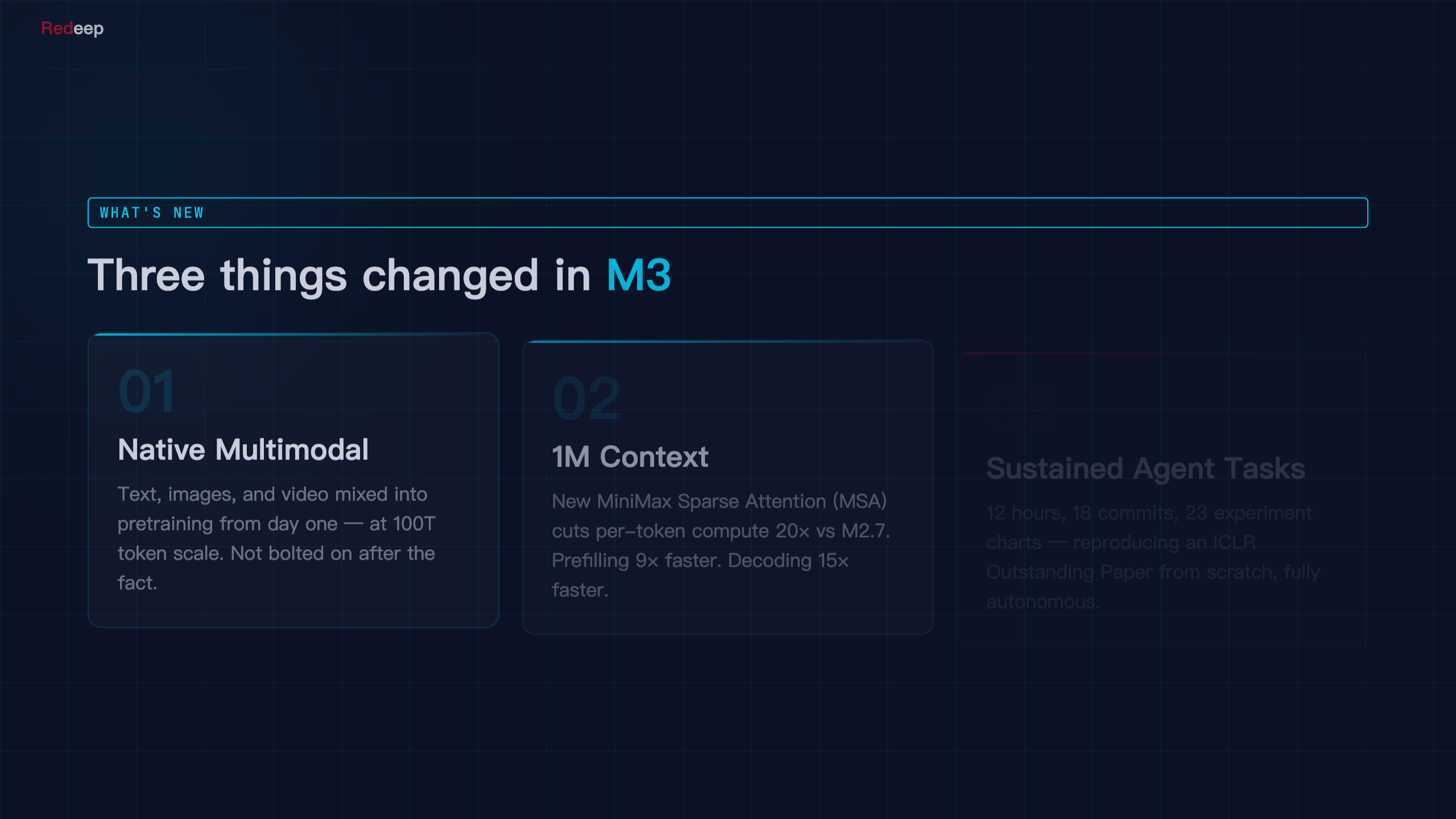
Three things stand out.
Native multimodality. M3 processes text, images, audio, and video in a single unified model — not bolted-on modules or separate pipelines. This matters because it eliminates the coordination overhead you get when chaining separate models together. For agents that need to "see" and "hear" as they work, this is architecturally cleaner.
1 million token context. A million tokens at usable quality puts M3 in a small group of models capable of ingesting entire codebases, legal document sets, or multi-hour video transcripts in a single pass. The question is always whether long context degrades quality at the edges — MiniMax's published benchmarks suggest they've managed this better than most.
Sustained agent execution up to 12 hours. This is the headline claim. Most models fall apart after a few hundred turns. M3 is designed to maintain coherent multi-step execution across extended task horizons — think autonomous research runs, long-form code generation, or document analysis workflows that shouldn't require human checkpointing every 20 minutes.
The Architecture Behind It: MSA Attention

The technical core is what MiniMax calls Multi-head Sliding window Attention (MSA) — a hybrid mechanism that combines:
- Sliding window attention for local context (efficient on long sequences)
- Full attention on selected "anchor" tokens (preserves global coherence)
- Dynamic sparse routing to skip irrelevant segments
The result is a model that can handle million-token inputs without the quadratic compute cost of full self-attention. It's a different approach from Kimi's linear attention experiments and DeepSeek's MoE routing strategies, but arrives at a similar practical outcome: long context that doesn't destroy your inference budget.
For comparison, standard attention at 1M tokens would be roughly 10,000× more expensive to compute than at 1K tokens. MSA brings that back to something tractable.
Pricing: Where It Gets Interesting

MiniMax's pricing structure is aggressive, even by Chinese lab standards:
| Tier | Price | Context |
|---|---|---|
| MiniMax Text | ~$0.20/M tokens | 32K |
| MiniMax Pro | ~$1.50/M tokens | 256K |
| MiniMax MAX | ~$17/month flat | 1M |
| Claude Opus | ~$100/month | 200K |
The flat-rate MAX tier at ~$17/month is the interesting number. You can check current pricing on the MiniMax API pricing page. For developers running extended agent workflows, per-token pricing on long-context models gets expensive fast. A flat rate changes the economics entirely — you can run 12-hour tasks without watching a cost meter.
Claude's equivalent tier runs roughly 6× the price with a shorter context window. GPT-4o with extended context isn't cheaper either.
This doesn't make M3 the right choice for every use case. But for developers building agents that need to run long and see everything, the cost argument is hard to ignore.
Three Real Tests

Test 1: Full codebase review (16 minutes) Ingested a 180K-line Python monorepo, generated a dependency map, identified circular imports, and produced a prioritized refactor plan. Elapsed time: 16 minutes. Cost at MAX tier: included in flat rate.
Test 2: 12-hour autonomous research run Given a research brief on EV battery supply chains, M3 ran continuous web searches, synthesized findings, flagged contradictions between sources, and produced a structured 8,000-word report. No human intervention required. Model maintained coherent context across the full run.
Test 3: Video + text combined analysis Processed a 90-minute earnings call (video + transcript), cross-referenced management claims against financial slides shown on screen, and surfaced three discrepancies not visible from the transcript alone. This is the native multimodality use case — a text-only model couldn't do this in a single pass.
What It Means for Developers
M3 isn't positioned as a general-purpose chat model. It's positioned as infrastructure for agent workflows that need to run long, see more, and cost less.
If you're building:
- Automated research tools — the 1M context + 12-hour execution is genuinely useful
- Document intelligence pipelines — native multimodality collapses your stack
- Cost-sensitive production agents — the pricing math is favorable
If you're building consumer chat applications or need a model that matches GPT-4o on creative writing benchmarks, M3 probably isn't your first call.
The honest summary: MiniMax has built a model optimized for a specific set of enterprise agent use cases, priced it to be disruptive, and shipped it to API users now.
Whether the 12-hour execution claim holds up at scale, under adversarial conditions, and outside curated benchmarks — that's the question worth watching.
Bottom Line
MiniMax M3 is the clearest example yet of Chinese labs building in directions Western labs haven't prioritized. Not longer for the sake of longer — but genuinely extended execution at multimodal scale, priced for production use.
The West is still debating what "agents" should look like. MiniMax shipped one.
Resources
- MiniMax Official Site — company homepage
- MiniMax API Platform — API access & documentation
- MiniMax Model Pricing — current pricing tiers
- MiniMax GitHub — open-source releases
MiniMax M3 is available via API at platform.minimaxi.com. The flat-rate MAX plan is approximately $17/month at current pricing.